
티스토리 뷰
집합연산자
집합연산자 : 쿼리와 쿼리를 더한다
조인 : 테이블과 테이블을 더한다.
table1 컬럼과 table2 컬럼, 즉 여러 테이블의 컬럼을 합치고 싶을 때가 JOIN이라면
집합연산자는 table1의 특정 행과 table2의 특정 행을 합치는 것(=쿼리 구문과 쿼리 구문의 합)
| UNION/UNION ALL | 첫번째 쿼리 결과와 두번째 쿼리 결과를 모두 출력하는 연산자 (합집합) |
| INTERSECT | 첫번째 쿼리 결과와 두번째 쿼리 결과의 공통 부분을 출력하는 연산자 (교집합) |
| MINUS | 첫번째 쿼리 결과에서 두번째 쿼리 결과를 뺀 부분을 출력하는 연산자 (차집합) |
집합 연산자 규칙
1. SELECT 절에 있는 컬럼 리스트(표현식 개수)가 일치해야한다.
- 열이 두 테이블 중 하나에 없는 경우 TO_CHAR 함수같은 변환함수를 사용해 데이터 유형을 일치시켜도 된다.

null이 아닌 임의의 이름을 붙여 사용해도 된다.

2. 같은 컬럼에 출력되는 데이터타입이 같아야 한다.
집합연산자 사용방법 (세미콜론 위치 주의할 것)
SELECT emp_id, last_name
FROM emp
WHERE d_id = 50
[집합연산자]
SELECT dept_id, d_name
FROM dept;
위 SELECT 문의 컬럼과 밑 SELECT 문의 컬럼 개수가 같으니 가능!
emp_id와 dept_id가 int, last_name, d_name이 varchar2로 데이터 타입이 동일하니 가능!
사용 시 주의점
- 쿼리간의 우선순위는 동등하기 때문에 하나의 쿼리문에 있으면 순서대로 출력된다.
- 먼저 실행되길 원하는 구문은 ( ) 괄호로 지정해주면 우선순위가 높아진다.
- 정렬(order by)을 하고 싶으면 쿼리 구문의 가장 마지막에 써야한다.
컬럼명은 어떻게 지정될까?
첫번째 쿼리 구문에 있는 컬럼명이나 alias가 출력된다! - 첫번째 쿼리에 컬럼명 지정을 해주면 되겠지?
order by의 정렬의 기준이 되는 것 또한 첫번쨰 쿼리 구문이다.
위 집합연산자가 쓰여진 쿼리문에서는 order by를 쓸 때 emp_id나 last_name을 기준으로 작성해야 한다는 뜻!
UNION 사용 시 첫번째 쿼리문과 두번째 쿼리문의 중복된 데이터가 출력되지 않고,
중복된 행을 제거하는 연산자들은 출력하는 컬럼대로 오름차순으로 자동 정리해준다.
UNION ALL 사용 시 중복된 데이터는 중복된 채로 출력되기 때문에 정렬이 지원되지 않는다.
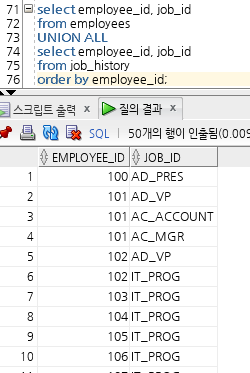
INTERSECT 또한 중복된 데이터를 한번만 출력되게(중복데이터 제거) 하고 정렬이 제공된다.
예전에 담당했던 업무를 지금 담당하고 있는 리스트

예전에 담당했던 업무를 현재도 담당하고 있되, 부서도 바뀌지 않은 멤버 조회

담당업무를 변경한 적 없는 사원 조회
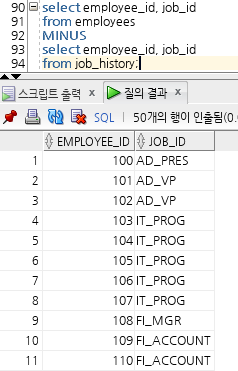
담당업무를 변경한 적이 있는 사원 조회

사원이 소속되어있지 않은 빈 부서 리스트 출력

'배운 것 기록 > DB' 카테고리의 다른 글
| [Oracle] 서브쿼리 관련 (1) | 2022.09.14 |
|---|---|
| DB 정리용 (0) | 2022.09.12 |
| [Oracle] 다른 DB 접속하는 방법 / DB 전환 / echo (0) | 2022.09.02 |
| [Oracle] DB 종료 / DB 생성 (0) | 2022.09.01 |
| [Oracle] ROLE (0) | 2022.08.30 |